

以前、stable diffusionの環境を構築しました。
ご覧いただいた方ありがとうございます。
今回はUIの説明をしようかと思います。
基本的なUI
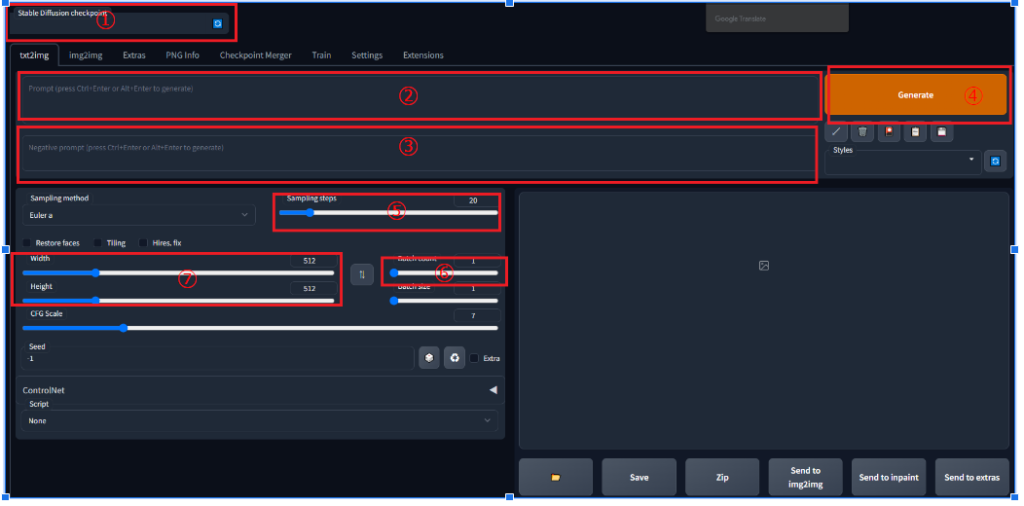
①使用する学習モデルを選択する
②画像内に表示したいものを入力
③画像内に表示したくないものを入力
④画像生成実行
⑤画像生成工程数20~30が良いようです
⑥生成する画像の枚数
⑦画像のサイズ横にでかいと複数の人物が出現しやすくなるので、縦長で練習するのがおすすめです。
便利な機能の紹介
PNGタブをクリックするとこの画面になります。
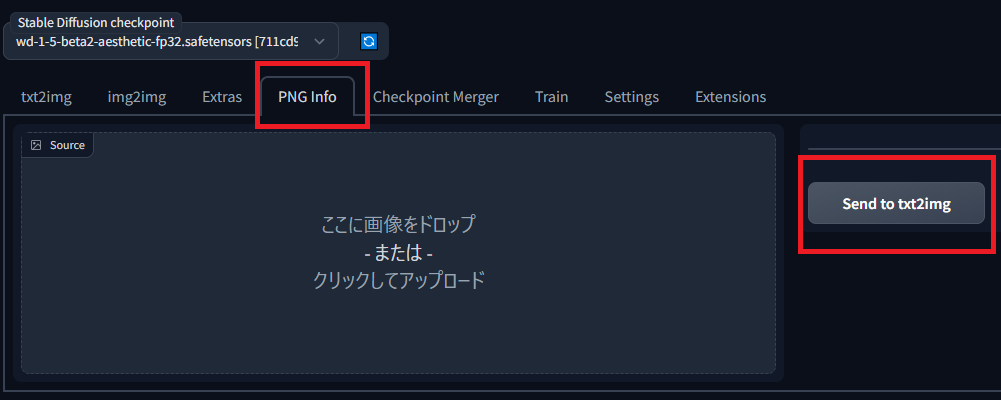
AIに生成させた画像をここにドロップすると、呪文などの情報をみることができます。
つまり、ネットで気に入った画像を覗き見し放題ですね。
また、自分自身でうまくいった画像をドロップし、send to txt2imgを押すことで設定を読み込むことができます!
白いもやが映らないようにする方法
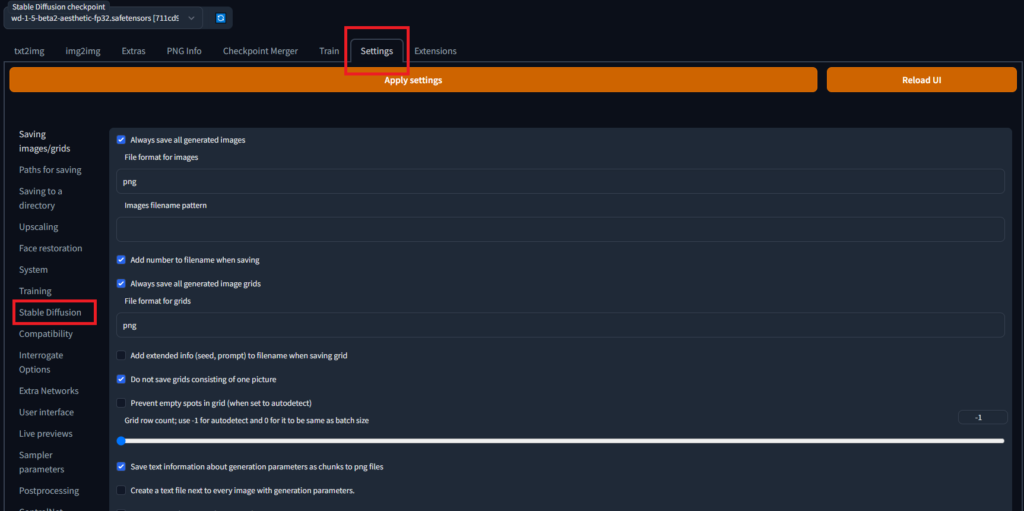
Settingsタブを選択すると、上記画像の画面になります。
そうしましたら、左側のstable diffusionタブを押してください。
下記画像画面に遷移します。
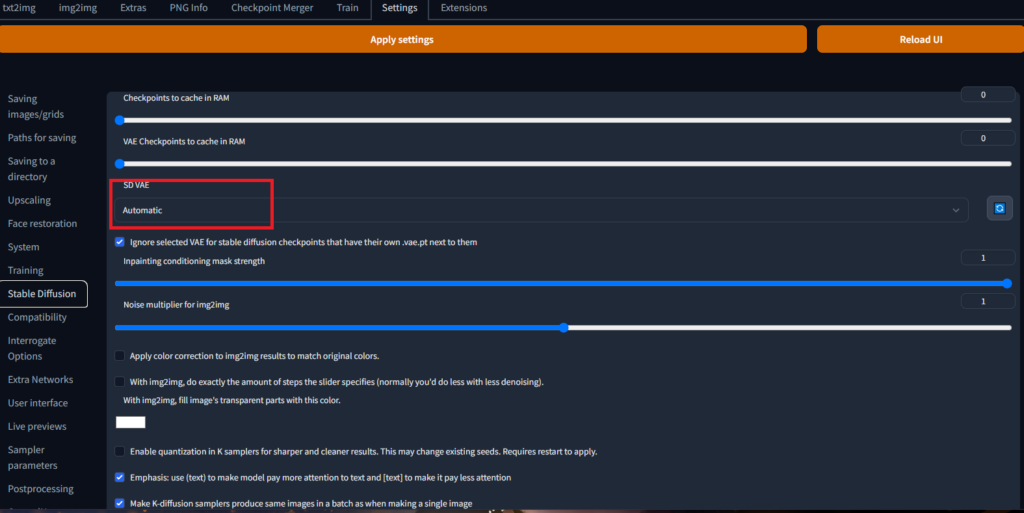
Automaticとなっていますね、こいつのせいです。
学習データを取得したサイト内に、VAEというファイルが置いてあるのでダウンロードしてください。

その後、下記ディレクトリにぶち込んでください。
stable-diffusion-webui/models/VAE
SD VAEに追加したものが見えるようになるので、そちらを使用することで改善します。
呪文紹介
学習データが二次元よりであればanime、三次元ならrealisticをいれるとよいです
共通でおすすめなワードは4k。高画質になります。
それをベースにポーズ、髪型、髪色、恰好、場所を足していく流れになります。
少ないワード数にした方が良いものが出る印象です。
矛盾するワードを入れると奇形になる確率が上がるので気を付けましょう。
下記に例を紹介。
ポジティブ:4k,anime,In town,city,lots of buildings,girl,hoodie,gorgeous
ネガティブ:(low quality,worst quality, trembling),distorted,ugly,additional limbs,additional waist,curved legs,curved hips,curved,additional knee,octopus,squid,Spiderl,additional breast
学習モデルはwaifudiffusionでこのような画像が出力されます。

参考になれば幸いです。





