

概要
こちらのLlama3.1とLlama3を比較する記事を読んでいただいた方、ありがとうございます😎
Llama3、Llama3.1の8Bモデルは、Mac Book Air(管理人の)で動かすことができませんでした。
その後軽量モデルがリリースされており、今回はLlamaの軽量モデルLlama 3.2 1Bを紹介します。
実を言うと、リリース後試してXにツイートしてますが記事にするのが遅れました。
DEMO
動作環境
なんのカスタムもしていない、M2 Mac Book Air
CPU:M2
SSD:256GB
メモリ:8GB
Q1:こんにちは

Q1の質問に対しては、問題ない回答です。
Q2:今日はすごく寒いです。 何か良い対策はありますか。

意味不明です。
Q2の回答は問題ありです。とはいえそれらしい回答を作ろうとした片鱗は感じました。
Q3: 寒いをテーマにした、歌の歌詞を作成してくれますか?
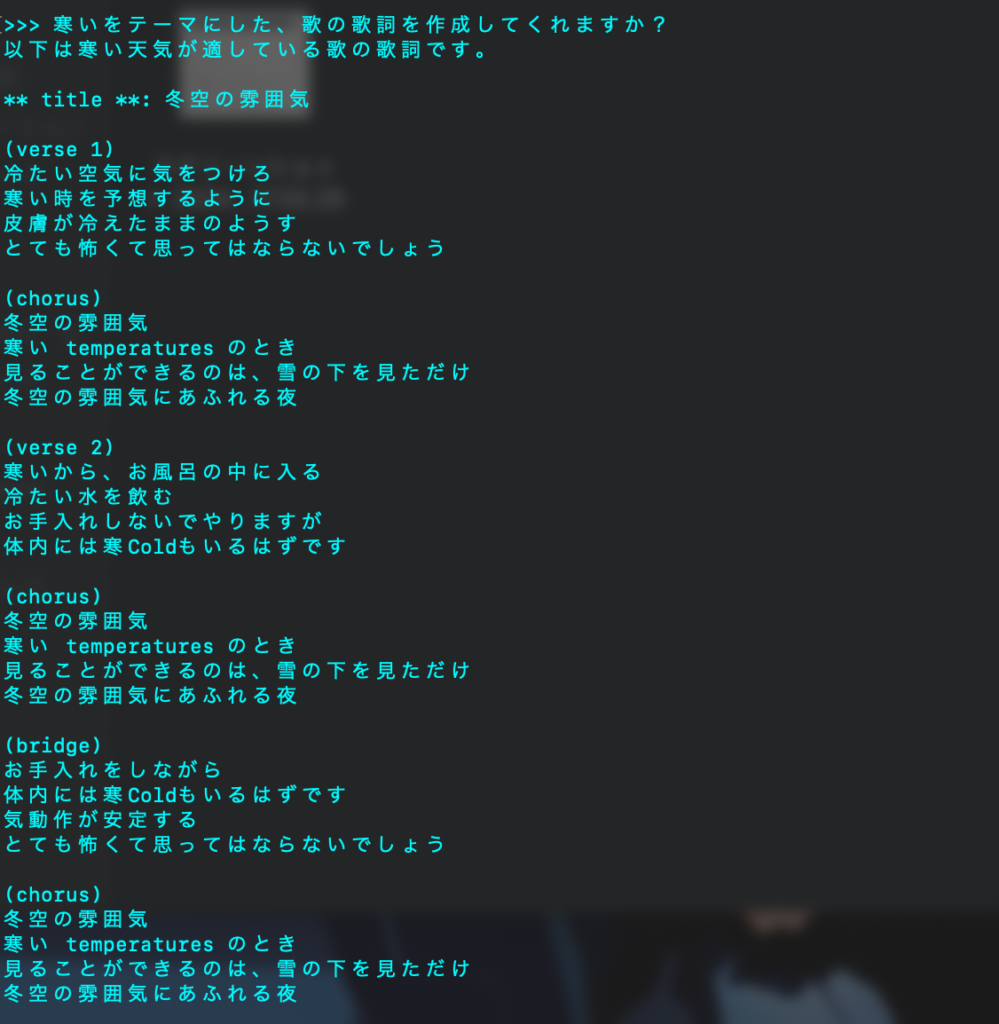
ちょっと変ですが、歌の歌詞なので英語と日本語が混ざるのは逆に良いかもしれない。
応答速度はこんな感じです。
Suno AIで遊ぶ時、Geminiに歌詞を作らせていますが、Llama3.2:1bもなかなかの速度で応答してくれました。
※動画の速度に変更等は加えておりません。
ちなみに、同環境で8Bモデルを実行しようとするとこうなります。
メッセージを見る限り、メモリ16GB以上のMacなら動きそう。

環境構築方法
1.Ubuntu:20.04の環境を整える
2.Lama 3.2 を動作させるためのスクリプトをダウンロード
3.Lama 3.2を実行!
- 1.Ubuntu:20.04の環境を整える
-
Ubuntu:20.04のダウンロード
docker pull ubuntu:20.04コンテナの作成
docker run -it -d --name コンテナの名前 -p 3000:11434 ubuntu:20.04コンテナの中に入る
docker exec -it コンテナの名前 /bin/bash初期作業としてアップデート・curlコマンドのインストールを実行
apt update apt upgrade apt install curl - 2.Llama 3.1 とLlama 3を動作させるためのスクリプトをダウンロード
-
curl -fsSL https://ollama.com/install.sh | sh - 3.Llama 3.2を実行!
-
ダウンロードしたプログラムを起動します。
ollama serve -
Llama 3.2:1bの起動コマンド(初回はダウンロードが実行されます。)
ollama run llama3.2:1b※インストール済みの2回目は、即起動します。
インストールが終わると「send a message」と表示されます。
質問をすると返答が返ってくる状態になります。

まとめ
少し触っていて分かったのですが、質問した内容は次の回答時に影響を与えるようです。
なんでだろ、、、このレベルだと要改善です。
ただ、これノートPC上で動作してるのですよ。
正直感動してます。
皆さんも、なかなかの性能だと思いませんか?
現状の軽量モデルは要改善ですが、近い将来改善すると思います。
AIの進化スピードには、目を見張るものがありますからね!
1年後にどうなるか楽しみです。





